Overall Architecture
CredSweeper is largely composed of 3 parts as follows. (Pre-processing, Scan, ML validation)
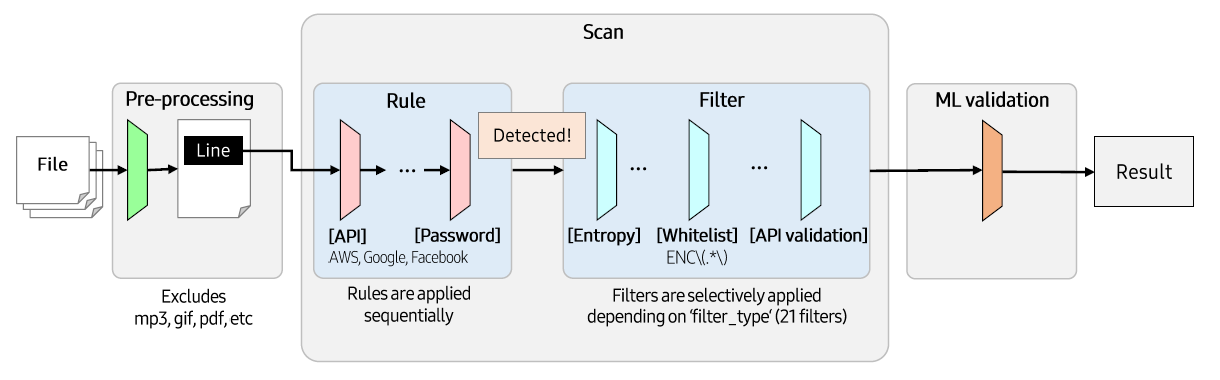
Pre-processing
When paths to scan are entered, get the files in that paths and the files are excluded based on the list created by config.json.
config.json
- exclude
pattern: Regex patterns to exclude scan.
containers: Extensions in lower case of container files which might be scan with –depth option
documents: Extensions in lower case of container files which might be scan with –doc and/or –depth option
extension: Extensions in lower case to exclude scan.
path: Paths to exclude scan.
source_ext: List of extensions for scanning categorized as source files.
source_quote_ext: List of extensions for scanning categorized as source files that using quote.
find_by_ext_list: List of extensions to detect only extensions.
check_for_literals: Bool value for whether to check line has string literal declaration or not.
line_data_output: List of attributes of line_data for output.
candidate_output: List of attributes of candidate for output.
...
"exclude": {
"pattern": [
...
],
"containers": [
".gz",
".zip",
...
],
"documents": [
".docx",
".pdf",
...
],
"extension": [
".7z",
".jpg",
...
],
"path": [
"/.git/",
"/.idea/",
...
]
}
...
Scan
Basically, scanning is performed for each file path, and it is performed based on the Rule. Scanning method differs from scan type of the Rule, which is assigned when the Rule is generated. There are 3 scan types: SinglePattern, MultiPattern, and PEMKeyPattern. Below is the description of the each scan type and its scanning method.
- SinglePattern
When : The Rule has only 1 pattern.
How : Check if a single line Rule pattern present in the line.
- MultiPattern
When : The Rule has 2 patterns.
How : Check if a line is a part of a multi-line credential and the remaining part exists within 10 lines below.
- PEMKeyPattern
When : The Rule type is pem_key.
How : Check if a line’s entropy is high enough and the line have no substring with 5 same consecutive characters. (like ‘AAAAA’)
Rule
Each Rule is dedicated to detect a specific type of credential, imported from config.yaml at the runtime.
config.yaml
...
- name: API
severity: medium
confidence: moderate
type: keyword
values:
- api
filter_type: GeneralKeyword
use_ml: true
min_line_len: 11
required_substrings:
- api
target:
- code
...
Rule Attributes
- severity
-
... class Severity(Enum): CRITICAL = "critical" HIGH = "high" MEDIUM = "medium" LOW = "low" ...
- confidence
Confidence - The manually configured value indicates the confidence that the found candidate could be the credential type.
... class Confidence(Enum): STRONG = "strong" MODERATE = "moderate" WEAK = "weak" ...
- type
-
... class RuleType(Enum): KEYWORD = "keyword" PATTERN = "pattern" PEM_KEY = "pem_key" MULTI = "multi" ...
- values
keyword : The keywords you want to detect. If you want to detect multiple keywords, you can write them as follows : password|passwd|pwd.
pattern : The patterns you want to detect. For more accurate detection, it is recommended to specify ?P<value> in the patterns : (?P<value>AIza[0-9A-Za-z-_]{35}).
pem_key : Specific rule to find multiline PEM private keys.
multi : Two patterns you want to detect. Candidate will be found only if second pattern matched nearby.
- filter_type
The type of the Filter group you want to apply. Filter groups implemented are as follows: GeneralKeyword, GeneralPattern, PasswordKeyword, and UrlCredentials.
- use_ml
The attribute to set whether to perform ML validation. If true, ML validation will be performed. If false - ml_probability will be set to None in report.
- min_line_len
drop too short stripped lines before text search to increase performance
- required_substrings
any strings has to be found in a line before regex search to increase performance
- target
code : The rule will be applied without –doc option
doc : The rule will be applied with –doc option
Filter
Check the detected candidates from the formal step. If a candidate is caught by the Filter, it is removed from the candidates set. There are 21 filters and 4 filter groups. Filter group is a set of Filter_s, which is designed to use many Filter_s effectively at the same time.
ML validation
CredSweeper provides pre-trained ML models to filter false credential lines.
ML validation is on by the default and its sensitivity can be adjusted using --ml_threshold:
--ml_threshold THRESHOLD_OR_FLOAT_OR_ZERO
setup threshold for the ml model.
The lower the threshold - the more credentials will be reported.
Allowed values: float between 0 and 1, or any of ['lowest', 'low', 'medium', 'high', 'highest']
(default: medium)
And ML can be fully disable by setting --ml_threshold 0
python -m credsweeper --ml_threshold 0 ...
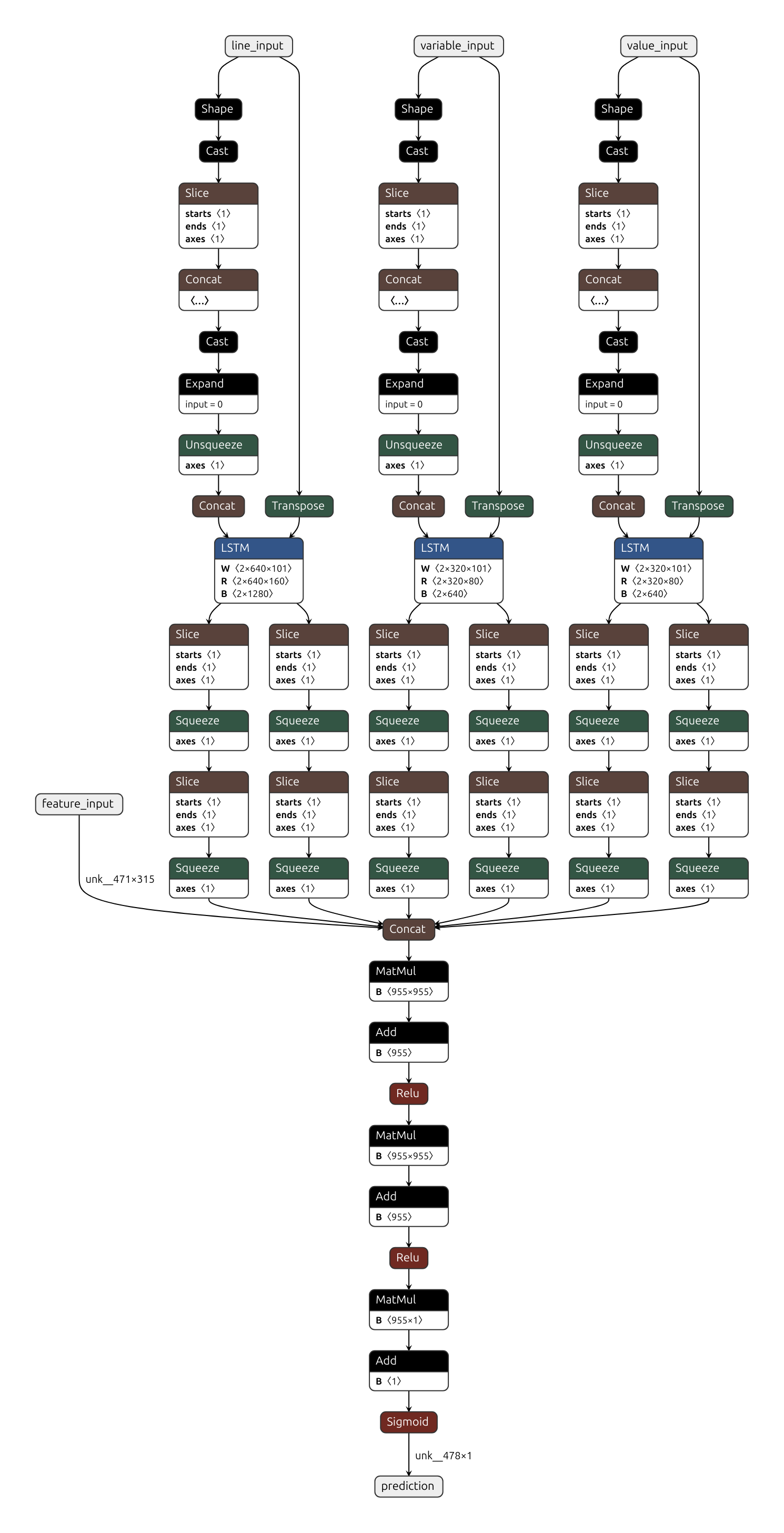
Our ML model architecture is a combination of Bidirectional LSTM with additional handcrafted features. It uses first 80 characters from the potential credential value and variable (if available), 160 characters from line around the value and configurable handcrafted features to decide if it’s a real credential or not.
Example (file leaked_cred.py):
my_db_password = "NUU423cds"
Steps:
Regular expression extracts
`NUU423cds`as a secret value,`my_db_password`as a variable, and`my_db_password = "NUU423cds"`as whole lineHandcrafted feature classes instantiated from classes in features.py using model_config.json. Instantiation process can be checked at ml_validator.py#L46. Features include:
` `character in line: yes/no,`(`character in line: yes/no, file extension is`.c`: yes/no, etc.Handcrafted features from step 2 used on line, value, variable, and filename to get feature vector of length 91
`NUU423cds`Configurable character set is applied + 1 padding character + 1 special character for all other symbols. Padded line than one-hot encoded. Link to corresponding code: MlValidator.encodePadded line from step 4 inputted to Bidirectional LSTM of value. The same encodings are performed for variable and line. LSTM produce 3 single vectors of lengths 80, 80, 160 as outputs
LSTM outputs and handcrafted features concatenated into a single vector
The vector from step 6 is fed into a stack of two sequential Dense layers, each with the number of output units equal to the number of input units.
Last layer outputs float value in range 0-1 with estimated probability of line being a real credential
Predicted probability compared to the threshold (see –ml_threshold CLI option) and credential reported if predicted probability is greater
Additional:
Handcrafted features are based on the rules described in “Secrets in Source Code” publication.
@INPROCEEDINGS{9027350,
author={Saha, Aakanksha and Denning, Tamara and Srikumar, Vivek and Kasera, Sneha Kumar},
booktitle={2020 International Conference on COMmunication Systems NETworkS (COMSNETS)},
title={Secrets in Source Code: Reducing False Positives using Machine Learning},
year={2020},
pages={168-175},
doi={10.1109/COMSNETS48256.2020.9027350}
}
Mapping between text threshold values and float can be found at model_config.json#L2. Values are based on F-0.25, F-0.5, F-1, F-2 and F-4 scores on CredData test